ThinkPHP 后端采集新华社客户端文章,PHP采集vue.js站点文章记录
guozi发表于:2024-05-11 17:37:17浏览:258次
最近学习了一下PHP后端采集html网页内容,在次做一个简单的记录
1、采集一般网站网页内容比如:https://www.gyxww.net/view/82084.html
用 file_get_contents 方法就可以获取到网页文件内容,分析网页源代码,然后用正则处理采集到的文件内容,分别把标题、提取标题图片、内容返回给前端
(正则不会写,不过能匹配到)
$arrContextOptions=array(
"ssl"=>array(
"verify_peer"=>false,
"verify_peer_name"=>false,
),
);
$html = file_get_contents($url, false, stream_context_create($arrContextOptions));
$data = [];
// title
$pattern = '/<title>(.*?)<\/title>/i';
if (preg_match($pattern, $html, $matches)) {
$data['title'] = $matches[1];
}
// content
$pattern = '/<div class="content">.*?<div class=\"h mt20\">/ism';
if (preg_match($pattern, $html, $matches)) {
$ok = preg_replace('/\\n/', '', $matches[0]);
$ok = preg_replace('/\ \ /', '', $ok);
$data['content'] = $ok;
}
// img
$pattern = '/<img .*?src=[\"|\']+(.*?)[\"|\']+.*?>/';
if (preg_match($pattern, $data['content'], $matches)) {
$data['img'] = $matches[1];
}
return $data;2、微信公众号内容的采集
$arrContextOptions=array(
"ssl"=>array(
"verify_peer"=>false,
"verify_peer_name"=>false,
),
);
$html = file_get_contents($url, false, stream_context_create($arrContextOptions));
$data = [];
// title
$pattern = '/<meta\s+property=\"twitter\:title\"\s+content\=\"(.+?)\"\s*\/?\>/';
if (preg_match($pattern, $html, $matches)) {
$data['title'] = $matches[1];
}
// img
$pattern = '/<meta\s+property="og:image"\s+content="([^"]+)"/i';
if (preg_match($pattern, $html, $matches)) {
$data['img'] = $matches[1];
}
// content
$pattern = '/<div\ class="rich_media_content[\s\S]*?div>/';
if (preg_match($pattern, $html, $matches)) {
$ok = preg_replace('/\\n/', '', $matches[0]);
$ok = preg_replace('/\ \ /', '', $ok);
$ok = preg_replace('/data-src/', 'src', $ok);
$ok = preg_replace('/hidden/', 'visible', $ok);
$data['content'] = $ok;
}
return $data;3、新华社客户端文章采集 文章地址:https://h.xinhuaxmt.com/vh512/share/12005919?homeshow=1&newstype=1001
新华社客户端大概是用vue.js开发,所有用 file_get_contents 采集不到的,得查看接口获取,通过用谷歌浏览器调试 network 获取到接口地址
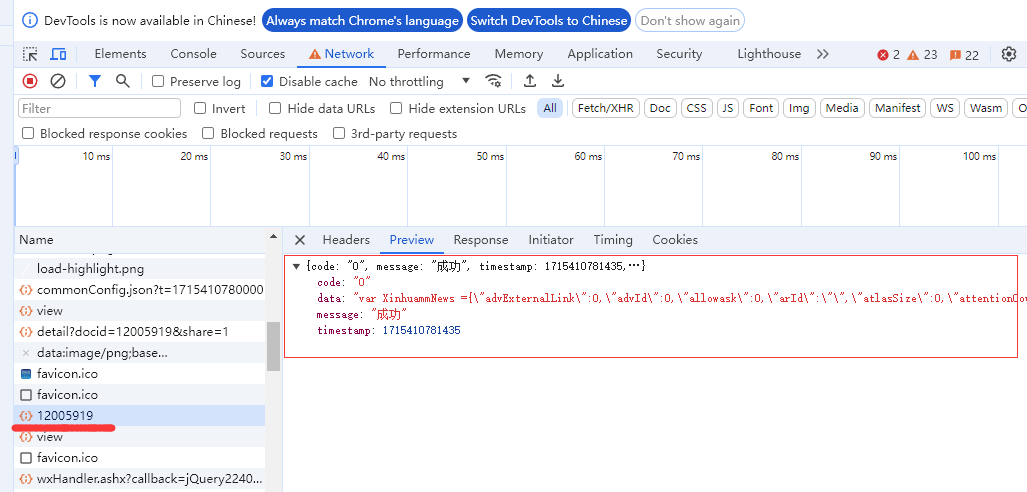
直接在浏览器打开接口地址,发现不能直接获取到数据,那么他们是用了签名算法了?

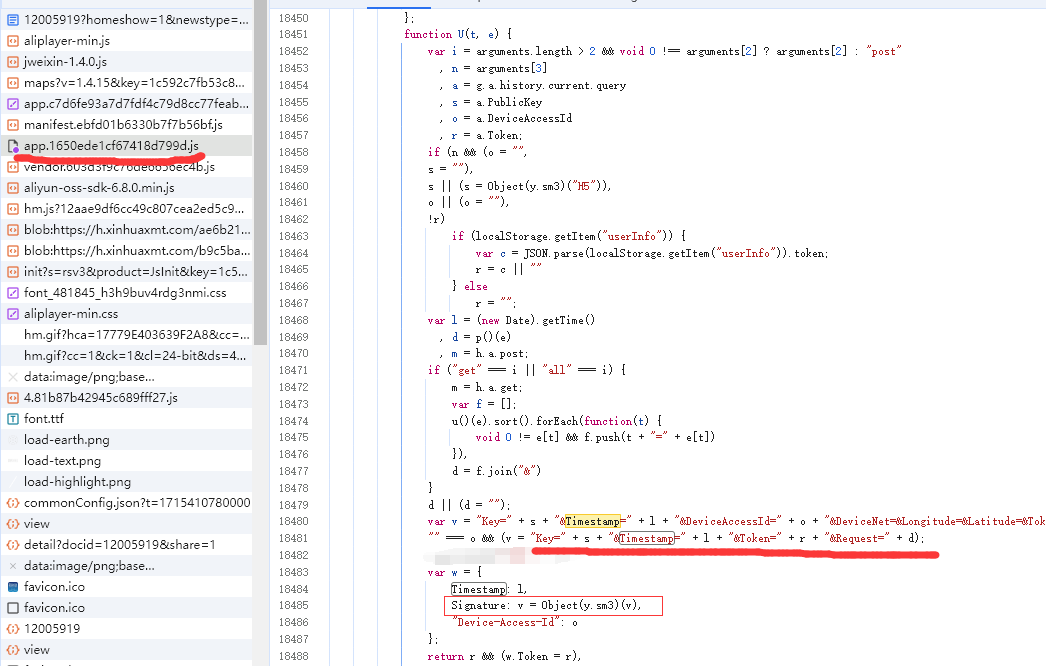
继续查看源代码

应该是vue.js生产的带签名的访问接口得到数据的,查看以 app开头的js文件
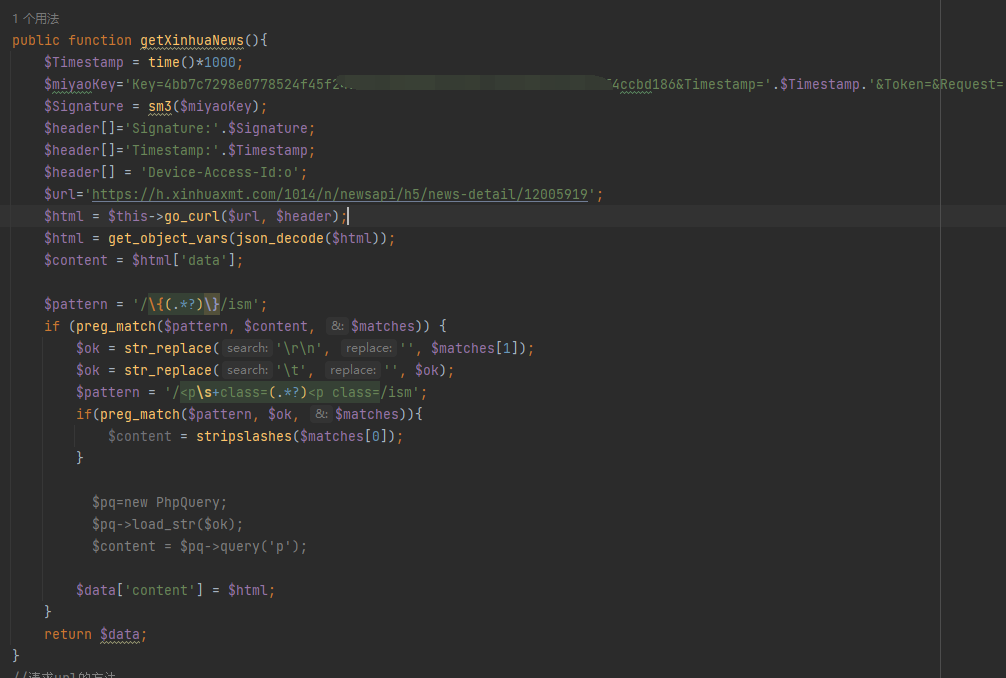

成功获取数据,欢迎交流:QQ:120287127

推荐文章
- 谷歌浏览器强制跳转到 https 的解决办法
- uniapp在谷歌浏览器测试出现/sockjs-node/info?t=1709704280949
- PHP微信公众答题系统、手机端网络答题系统
- 阿里云服务器如何利用安全组设置拦截IP(IP段)
- 如何关闭卸载360软件管家
- PHP利用 simple_html_dom 远程图片本地化
- ThinkPHP 后端采集新华社客户端文章,PHP采集vue.js站点文章记录
- element-ui 表格组件el-table操作toggleRowSelection事件会主动触发selection-change的坑
- centos7 服务器维护之查看最多流量访问IP地址,防止恶意访问IP
- 新闻APP源码,新闻门户网站开源系统ThinkPHP6框架UniAPP多端发布